
北京IT外包服务商带您了解环比增长率
| 2020-04-24 14:14:14 标签:
北京IT外包服务商带您了解环比增长率

很多企业比较注重自己的业务增长情况,时常会需要计算同比增长率和环比增长率。从上学的时候就有很多小伙伴搞不清楚这两个增长率之间的区别,这里简单直白的解释一下:
同比增长率从名字上就比较容易理解,指的是同期相比增长情况如何,比如今年一季度和去年一季度相比业务增长情况就可以用同比增长率来衡量,具体的计算公式为(今年一季度数据 - 去年一季度数据)/去年一季度数据。这里的季度只是举例用的,月份,周甚至天都可以作周期;
环比增长率的名字可能没有那么直观,它指的是这一个周期与上一个周期相比增长情Python如何计算环比增长率
况如何,比如第三季度和第二季度相比,业务增长情况就可以用环比增长率来衡量,具体计算公式为(第二季度数据 - 第一季度数据)/第一季度数据。当然这里的季度也只是举例用的,月份,周甚至天也都可以作周期。
根据具体表格情况计算环比增长率
我们不能确保每次拿到的数据都是类似的格式,对不同格式的数据在计算环比增长率的时候,会有一些小差别。
计算环比增长率情况一
首先看一下数据集长什么样子:
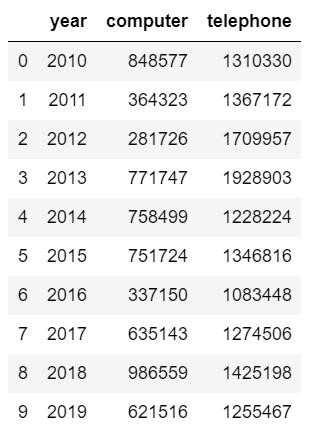
这是一种形式的表格,不同的年份,不同产品的销售额,对这样一种形式的数据计算环比增长率,是比较简单的一种形式,不需要提前对数据做过多的整理。
这里需要注意的是,我们希望能够保留年份信息,而用来计算的函数会把表格中所有数值型数据都进行环比运算,所以需要提前将年份信息转化成索引:
df1 = df.set_index("year") #为了不改变原数据,将充值索引后的数据赋值给df1df1 #查看修改索引后的数据集
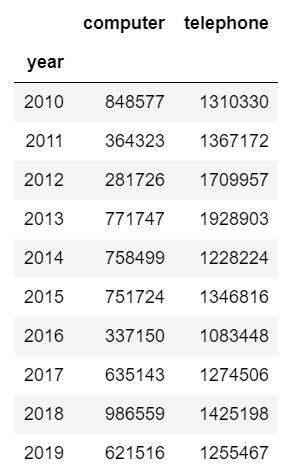
修改索引后的表可以直接进行计算了:
df1.pct_change() #pct_change()方法计算当前元素与先前元素之间的百分比变化
输出结果:
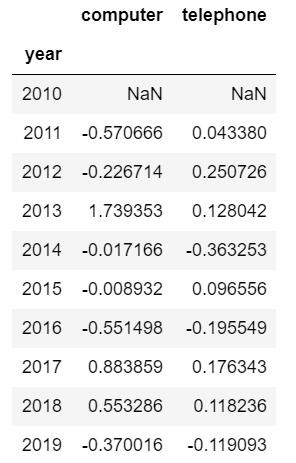
这样计算的就是每一年和前一年相比的一个环比增长率,当然实际工作中一般不会保留这么多位小数,需要处理一下:
round(df1.pct_change(),4) #保留四位小数,由于增长率一般是百分数,所以这里保留4位小数
输出结果:
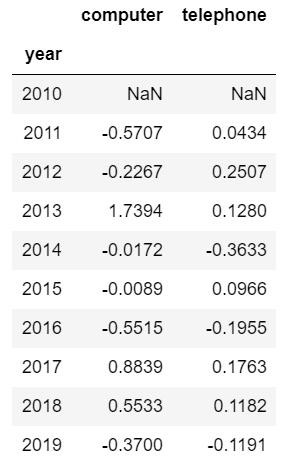
这样基本就是常见的环比增长率了。
计算环比增长率情况二
来看另一种样子的数据集:
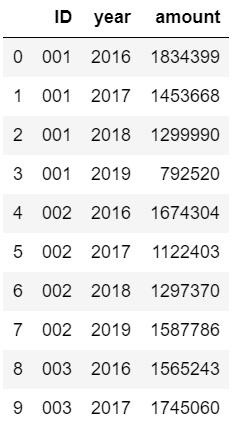
这一种数据集明显比上一个数据集复杂了一点,而且这是整个数据集的前十行,下边我们简单探索下这个数据集:
首先一目了然,一共有三列,分别是产品ID,年份,销售金额;
然后需要探索一共有多少个产品ID,即一共有几种产品,还有一共是几年的数据:
data.ID.unique() #产看有几种产品ID
输出结果:
array(['001', '002', '003', '004', '005', '006'], dtype=object)
一共有6种产品
data.year.unique() #查看一共有几年数据
输出结果:
array(['2016', '2017', '2018', '2019'], dtype=object)
一共有4年的数据。
那么这种数据要怎样计算环比增长率呢?
有两种方法,一种是将原数据集转化成第一种数据集情况的样子,第二种是不改变原数据集计算环比增长率
先看方法一
通过数据透视的方法,将原数据进行加工:
data1 = data.pivot(index = "ID",columns="year",values="amount" )data1 #为了不改变原数据,将数据透视后的结果赋值给data1
输出结果:
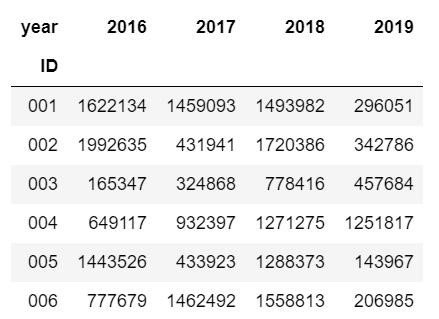
这里的行索引和列名可以进行互换,在data.pivot()的参数中进行设置就可以,虽然和第一种情况类似,但是仔细观察又发现了不同,第一种情况数据集的行索引是年份,这份数据中行索引是产品ID,其实这个是没有影响的,计算环比增长率的方法中有参数可以解决这种情况:
data1.pct_change(axis='columns') #只需要设置一下轴信息就可以改变运算方向
输出结果:
横向排列的就是每一个产品每一年的环比增长率,接下来,看另一种不对数据进行处理的方法。
再看方法二
由于一共是四年数据,规律明显,所以运用循环的方法计算环比增长率:
s = pd.Series() #新建一个空series用来放置计算结果for i in data["ID"].unique(): #行索引是产品ID,所以有多少种商品,就循环多少次 data_new = data[data["ID"]==i] #将相同产品的数据提取出来 s = pd.concat([s,data_new["amount"].pct_change()]) #计算一种产品的环比增长率,并价格计算出的记过拼接到series中s #查看最终结果
输出结果:
0 NaN1 -0.4793802 2.4026893 -0.2839624 NaN5 0.3867616 -0.1659267 -0.6011668 NaN9 0.09165510 -0.77360811 0.72302812 NaN13 -0.24101814 0.53450415 0.20014516 NaN17 0.03589918 -0.09147119 0.32854320 NaN21 -0.26149122 0.32679423 -0.903687dtype: float64
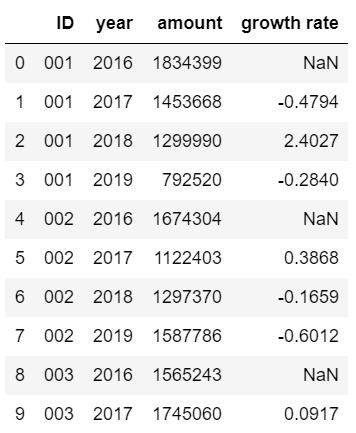
得出这个结果后,可以把结果作为一个新列添加到原表当中,方便对比查看:
data["growth rate"]=round(s,4)data.head(10) #由于数据集比较长,只查看前十行
输出结果:
另一个常用参数periods
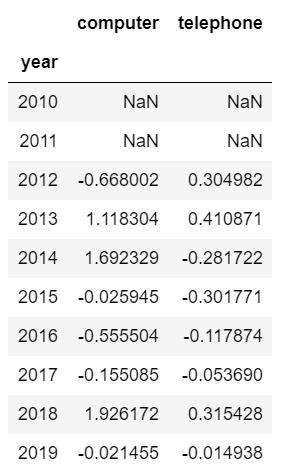
官方文档中对这个参数的解释是这样的:形成百分比变化所需的时间。用直白的话解释就是进行环比运算的周期,比如上边所有的计算都是下一个周期和上一个周期进行的环比增长,也可计算诸如第三期与第一期相比的环比增长,只需要设置periods=2,就可以实现这样的需求:
df1.pct_change(periods=2)#用第一个数据集为例,查看这个参数的效果
输出结果:
关于上述计算的所有结果,感兴趣的童鞋可以按照文章开头的公式手工计算一下,看下和pct_change()计算的结果都是一样的哦。
如何计算环比增长率是不是已经没有什么问题啦,YEAH!


